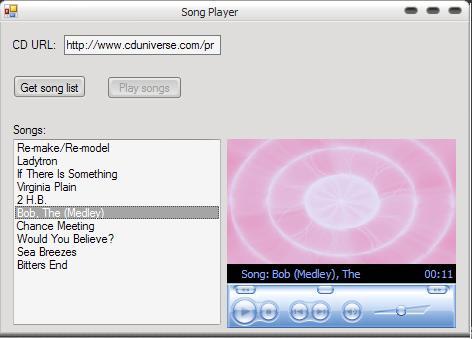
I was quite happy with this, but it only worked with CDUniverse, which was the original intent. The problem with this is of course that CDUniverse's repository of sound clips is hardly complete, in fact the AllMusicGuide database seems to have much more. I thought it would be easy to allow one to choose to use AMG, but in fact I came across something unexpected - now that AMG requires registration for access to most of its content, the program was shot, because merely copying the URL from my browser would lead to a innocuous enough page where the links to the sound clips were blank! (The way the program works is quite primitive - one has to actually navigate to the sample page via a browser, and then paste the URL into the program. The program isn't sophisticated enough to just get an album name and then determine the URL automatically - that, of course, has been left as a job for my other project) This morning, I chose the tried and true method of the cop-out, where I decided that for AMG, one would have to copy the source as an HTML file stored on the client's hard-drive, and then use that as the "URL". Messy, no?! Of course, it works, but I am disappointed that I haven't been able to come up with an unified interface for these two providers. I'd imagine that the music catalogue program would solve these problems because of the generality of the data you feed it, but still, I'd like for this stand-alone program to be cleanly designed too. At the very least, of course, I managed to implement a simple MVC pattern here, which was something painfully missing from the previous incarnation of my catalogue program.
As for where this fits in with the catalogue program, it should be fairly obvious - the idea is that one should be able to retrieve album information and play sample clips from the catalogue program. The problem I foresee is providing a nice way to give the user the choice of getting the samples from AMG or CDUniverse (or some other provider). I'm fairly confident that AMG has samples for most clips, but there are a few (from memory) where AMG doesn't even have a review, let alone clips. And, of course, the bigger problem is this whole registration business, and quite frankly I am at a loss as to how I can solve this problem. Ah, but I probably won't work on this for a while now, because my goal now is to try to use C# to make a revised version of something else I've worked on a lot - Tetris! I can't count the number of times I've started and stopped with this game, but darn it, this time I've got to be serious about finishing it and making sure it has no bugs!
I actually used the program as an excuse to try out the beta of Visual Studio .Net 2005 (the C# express edition, to be precise). My impressions so far have been quite favourable, indeed it seems to be at an almost equal footing with Eclipse in my eyes. The IntelliSense functionality seems to be vastly improved, and I feel that Eclipse would do well to add autocompletion at least after new statements. VS.Net also keeps local variables in the autocomplete list, and remembers your last selection, which I find very useful - it saves a lot of typing, especially when doing many Console.WriteLines!
I was going to say (before I realized how ludicrous the idea is) that the one little thing that annoys me is that double-clicking on a control (such as a textbox) automatically causes the editor to create an OnClick event, and take you to the code screen. Of course, this behaviour is a perceived benefit to users, but I wish there were a way for me to change the default behaviour to be merely editing the "most common" property - f'rinstance the Text property of a textbox. As I write this, and as I begin to comprehend how stupid and unfeasible this sounds, and wonder how on earth I come up with such thoughts.
I see that in this beta, C# supports generics, which is a welcome change; indeed, I thought they would have included it in the first standard, after seeing Java's approach. Indeed, with delegates in the mix, C# allows for statements much in the vein of STL algorithms, such as songs.ForEach (delegate (Song s) { Console.WriteLine (s.Name) }) - the fact that the delegate is anonymous is very convenient! Anonymous functions/functors are definitely something I'd like in C++ - speaking of changes to C++, Stroustrup has written an article detailing the design of C++0x. He admits that C++ as it stands can be a bit intimidating for novices, and seems to want to correct that to some extent. It sounds like one of the motivations behind Java - hiding the complexity of C++ so that programmers and non-programmers alike can write code at a reasonable level of abstraction, but I don't think we're going to see C++ morph slowly into Java*. Stroustrup has said many times that Java's goals are vastly different to that of C++, and that even if he could make C++ without maintaining backwards-compatibility with C, Java is not the language he would have come up with. Some of the tweaks he introduces in the document would be quite welcome. For instance, the vector initializer list. Boost of course provides the assign library that tries to do something similar, and my knowledgeable tutor tried to make a container that supported such initialization through a cunning use of the comma operator, so the desire for such a feature is clearly present.
* But are all languages morphing into Lisp? Again, I wish I would stop procrastinating and just learn the darn language already, so that I can make up my own mind instead of relying on other people's speculations.
